Whether the NVI data is representative is actually a very complicated question, and it is very difficult to give a simple yes or no. When we say “representative,” we just mean: do we think the answers we got would be similar if everyone who lived in Detroit took the survey? In this case, the answer is mostly yes—with a few things to keep in mind. Generally speaking, this data is representative overall, especially for the city as a whole and for each City Council district. That means the people who answered the survey give us a good idea of what most people in Detroit might say—if we had asked everyone. At the neighborhood zone level, the data is a little less representative, but still helpful.
That said, we know that some groups were more likely to take the survey than others. In our case, we know that the types of people who took our survey look different than Detoiters overall. That means if we are using the data to make decisions, we should remember where the data might not represent every voice equally.
A sample is a smaller group of people selected from a larger population to participate in a survey or study. Instead of asking everyone, we ask just a portion of the group and use their responses to make educated guesses about the whole population. When selected carefully, a sample can give us reliable insights—saving time, money, and effort while still helping us understand the bigger picture.
Sample size is the number of people included in a survey or study. It plays a key role in understanding if the results are reliable and accurate.
We want to know how many people we need to answer a question to be confident that if we did ask everyone in Detroit the same question, we would get similar results. This is where sample size comes in.
When we compare sample sizes to the population size , we can estimate how accurately our survey results reflect the entire population’s opinions. These comparisons happen through different calculations which tell us how much confidence we can have that the NVI results represent the entire City of Detroit.
Two important tools help us make this assessment: the margin of error (MOE) and the confidence interval.
In short, the sample size, or number of people who completed the survey, determines the size of the margin of error and confidence interval. Both of these measures together tell us how accurate our results are likely to be.
While it’s true that larger samples give us more precision, there’s a point where it doesn’t make sense to continue to collect surveys. After a certain size, adding more people doesn’t significantly improve accuracy, but it does increase time and cost for outreach. That’s why surveys aim for a sample that’s just large enough to provide reliable results without wasting resources. For more about these reliability measures, check out Data Driven Detroit’s blog post or this video.
For each council district and neighborhood zone, we calculated the sample size needed to meet certain confidence intervals and margins of error based on the overall population in each place. In the table below you can see which ones met the threshold. Overall, the number of surveys collected in each council district met the threshold of a 95% confidence interval and 5% margin of error. Sixteen neighborhood zones meet the threshold for an 80% confidence interval and 5% margin of error, seven zones did not meet the threshold.
| Council District | Surveys Collected | Surveys needed to meet a 95% confidence interval with 5% margin of error | Did we meet the 95% confidence interval with a 5% margin of error threshold? |
|---|---|---|---|
| 1 | 614 | 382.5 | Yes |
| 2 | 605 | 382.5 | Yes |
| 3 | 410 | 382.3 | Yes |
| 4 | 619 | 382.3 | Yes |
| 5 | 756 | 382.4 | Yes |
| 6 | 555 | 382.4 | Yes |
| 7 | 502 | 382.4 | Yes |
| Neighborhood Zone | Surveys Collected | Surveys needed to meet a 80% confidence interval with 5% margin of error | Did we meet the 80% confidence interval with a 5% margin of error threshold? |
|---|---|---|---|
| 1a | 212 | 163.2 | Yes |
| 1b | 153 | 161.8 | No |
| 1c | 249 | 162.3 | Yes |
| 2a | 248 | 162.4 | Yes |
| 2b | 193 | 162.0 | Yes |
| 2c | 164 | 162.0 | Yes |
| 3a | 167 | 162.3 | Yes |
| 3b | 150 | 162.1 | No |
| 3c | 93 | 161.8 | No |
| 4a | 194 | 162.3 | Yes |
| 4b | 230 | 162.0 | Yes |
| 4c | 195 | 161.9 | Yes |
| 5a | 248 | 162.2 | Yes |
| 5b | 224 | 162.0 | Yes |
| 5c | 284 | 162.2 | Yes |
| 6a | 154 | 162.2 | No |
| 6b | 227 | 161.8 | Yes |
| 6c | 120 | 162.1 | No |
| 6d | 54 | 159.6 | No |
| 7a | 209 | 162.2 | Yes |
| 7b | 104 | 161.9 | No |
| 7c | 186 | 162.2 | Yes |
However, we cannot say that our survey is representative based on these numbers alone, these numbers only work if certain things, which statisticians call assumptions, are true. In our case, we know that we don’t meet those assumptions, and we want to ensure that we are letting people know about those limitations.
All the calculations we’ve discussed—sample size, margin of error, confidence intervals—are based on an important assumption: that a sample is random. A truly random sample means that every person in the population had an equal chance of being selected to take the survey. When that’s true, we can feel confident that our results reflect the broader group.
But in reality, it’s hard to get a perfectly random sample—especially when doing community-based or opt-in surveys like ours. Most people who saw our survey likely had internet access and had previously signed up to receive emails from an organization, agency, or newsletter. This means our responses are not random and may over-represent certain types of people—especially those who are more digitally connected and don’t mind taking surveys.
To try and counteract that bias, we took additional steps. We promoted the survey at in-person events, made it available on paper, and sent random outreach emails to increase reach beyond our usual circles. These steps helped, but they didn’t eliminate the issue.
While we can still learn a lot from this data, it’s important to be transparent about the fact that our sample isn’t fully random. This affects how confidently we can say our findings apply to the whole population and not just those who took the survey.
After looking at our sample size and potential sources of bias, the next step is to examine how well the people who took the survey match the broader population. One way we assess this is by comparing the demographic characteristics of survey respondents—such as sex, age, and race—to the known demographics of the areas where they live.
For example, we know from broader research that women are more likely than men to take surveys. As a result, our data may reflect women’s experiences more than men’s, simply because women were more likely to respond. This is called oversampling, and while it’s common in community surveys, it’s still a limitation we need to acknowledge.
This analysis doesn’t fix the imbalance, but it gives us valuable insight into the strengths and limitations of the data—and helps guide future improvements in data collection and engagement.
In the tables below, we look at how closely the makeup of our sample aligns with the population in different geographies across the city, such as Council Districts and NVI Neighborhood Zones. This comparison helps us understand where our data may be more or less representative. If certain groups are consistently over- or underrepresented in particular areas, it may suggest a need for caution in interpreting results from those places.
When we look at the gender of people who took the survey citywide, we see that the City as a whole is 48% male and 52% female. This is according to the American Community Survey which is also a representative sample of the population (for margins of error, you can check out D3's State of the Child tool). The people who answered our survey were 74% female, 24% male, 1% non-binary, 1% prefer to self-identify. This means that women are over-represented in our sample. One thing we can do about this is to look at the impact of gender on a survey answer, which means that we recalculate that indicator twice, once using only female respondents and once using only male respondents. This allows us to determine how much or how little the gender difference impacts that particular indicator. To see the male/female gender breakdown by City council district, you can look at the charts below.
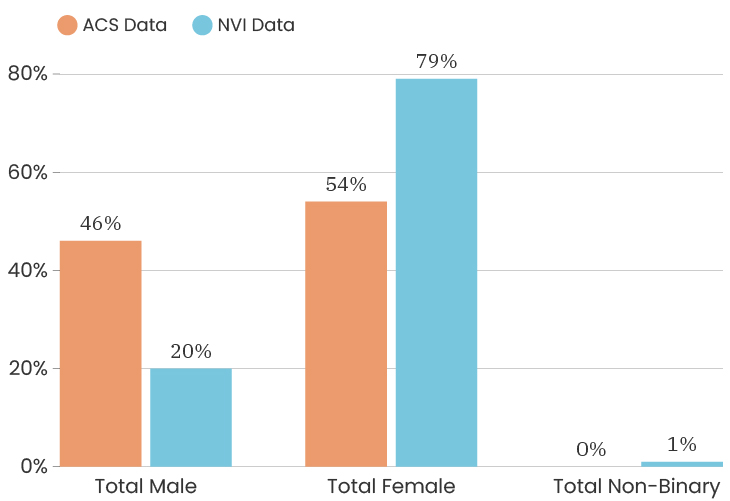
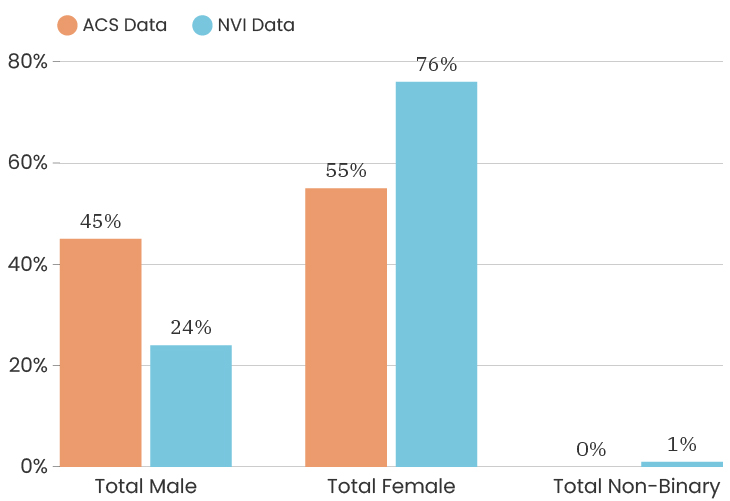
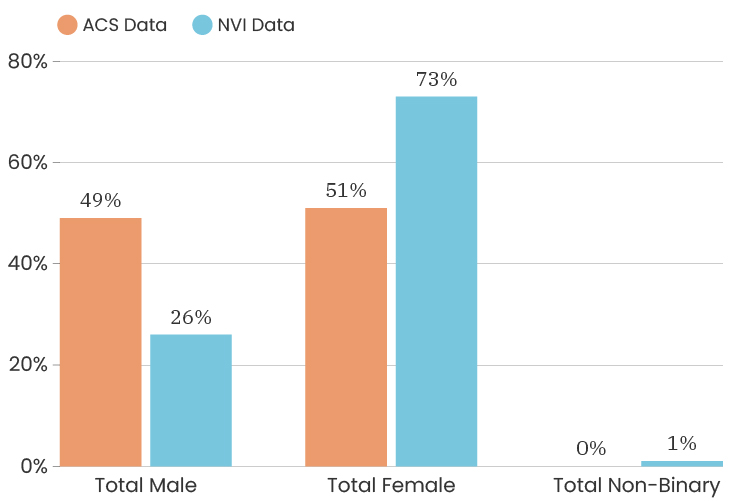
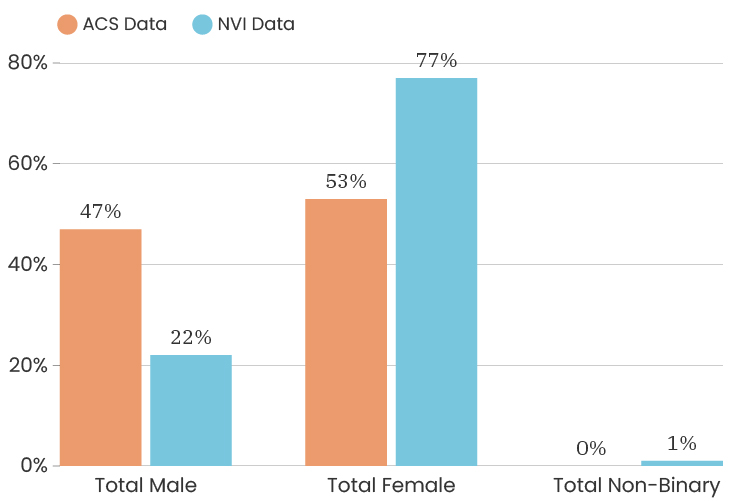
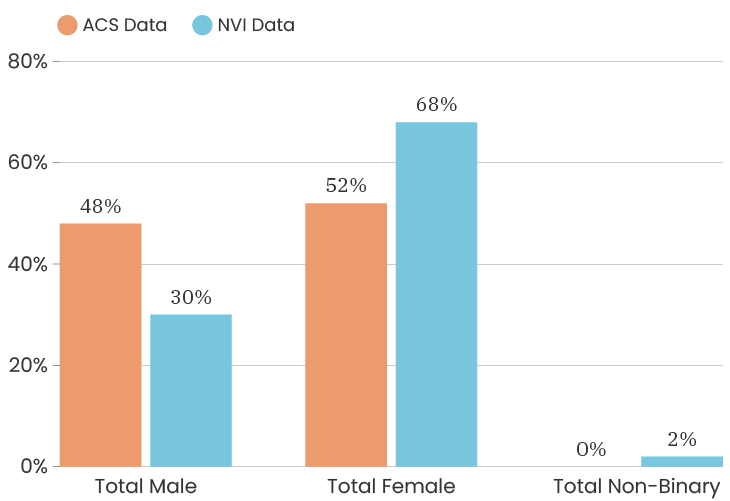
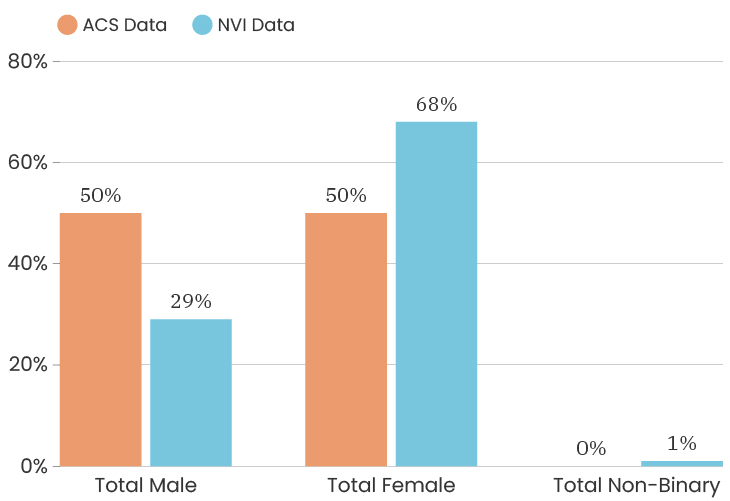
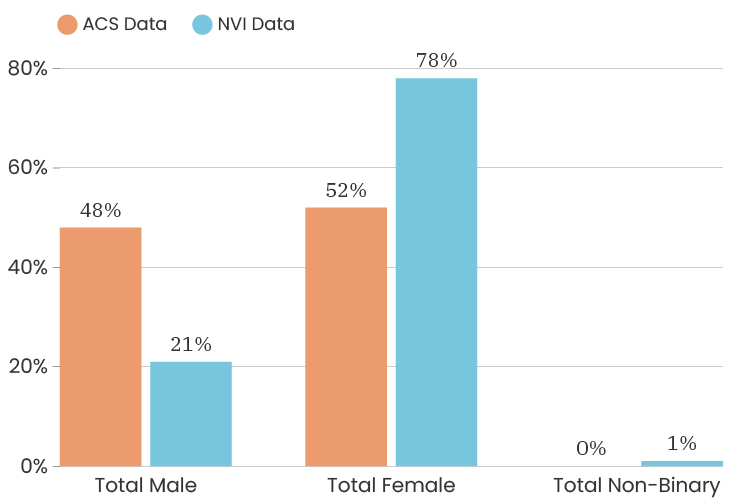
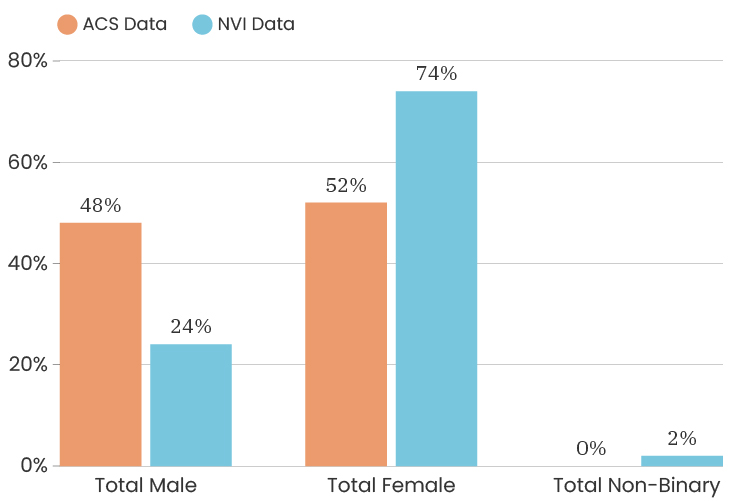
Citywide, the ACS data has median income for the City at $39,575. The people who took the NVI survey had a median income of $38,506, which puts us slightly below the City’s median income (and we are outside of the margin of error).
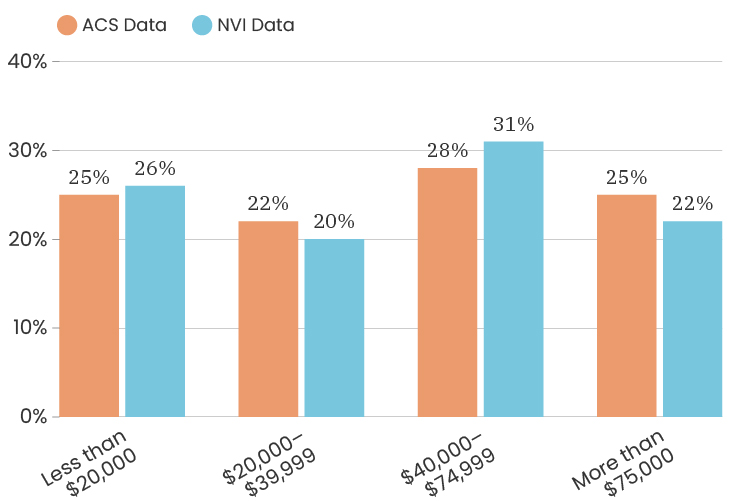
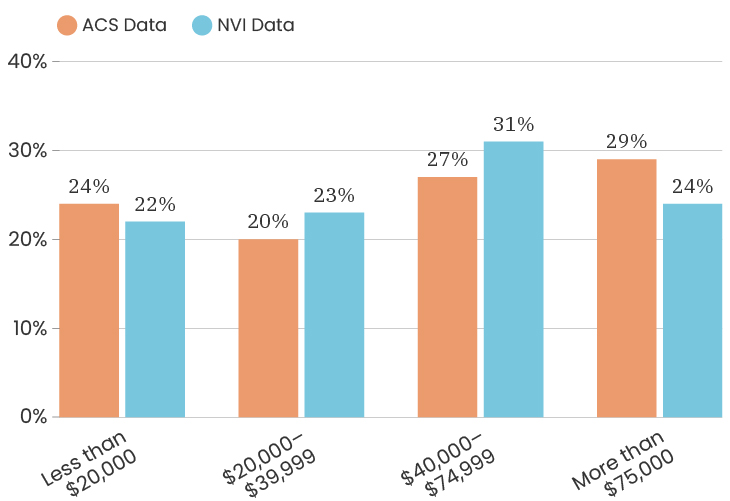
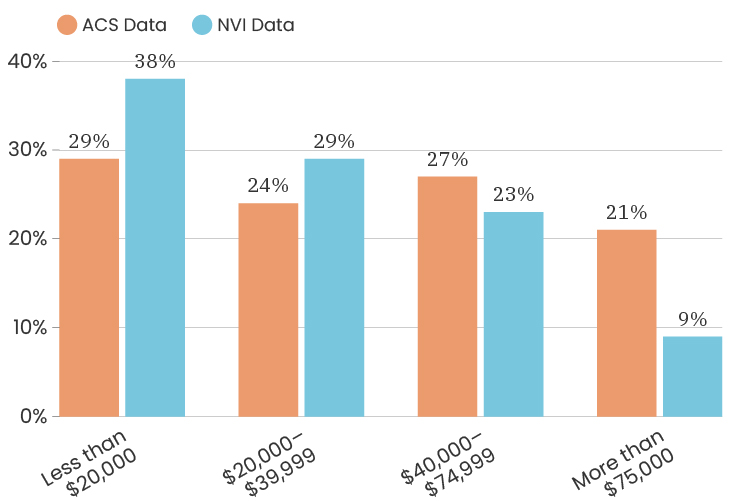
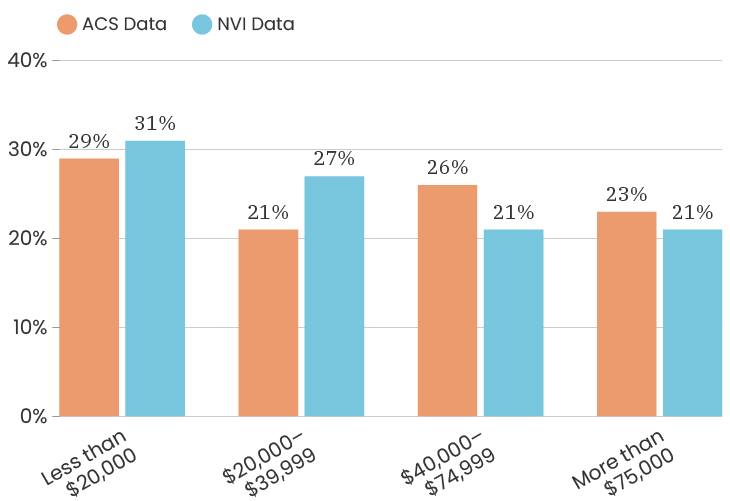
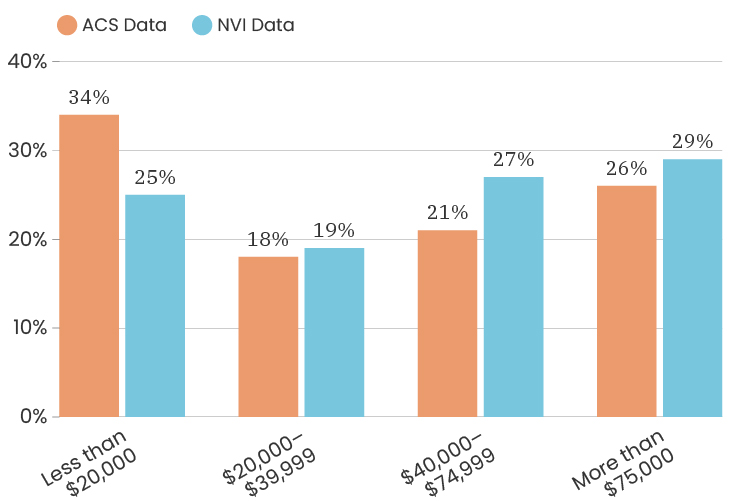
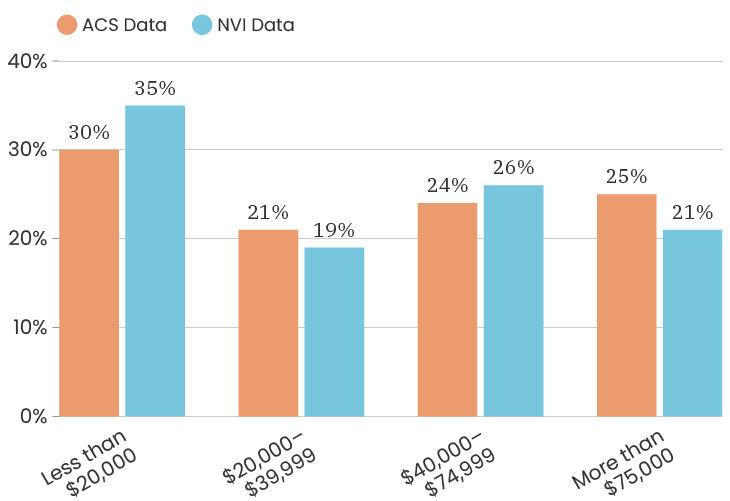
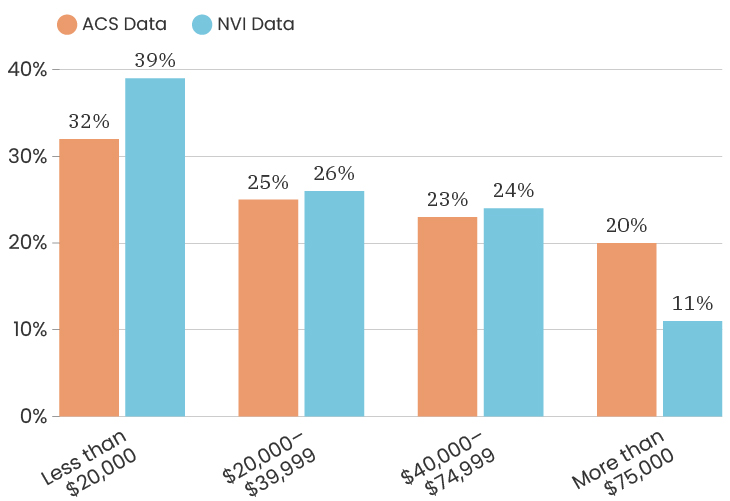
The median age for the City of Detroit is 35 years old. The median age of the people who took our survey is 50 years old. This means that people over the age of 50 are over represented in our sample. Like with gender, one thing we can do about this is to look at the impact of age on a specific indicator, which means that we recalculate that indicator twice, once using only respondents under 50 and once using only respondents over 50. This allows us to determine how much or how little the age difference impacts that particular indicator. To see the age breakdown by City council district, you can look at the charts below.
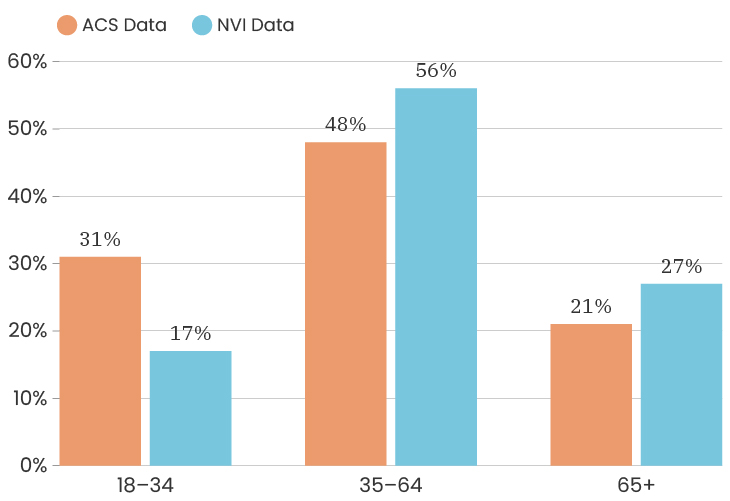
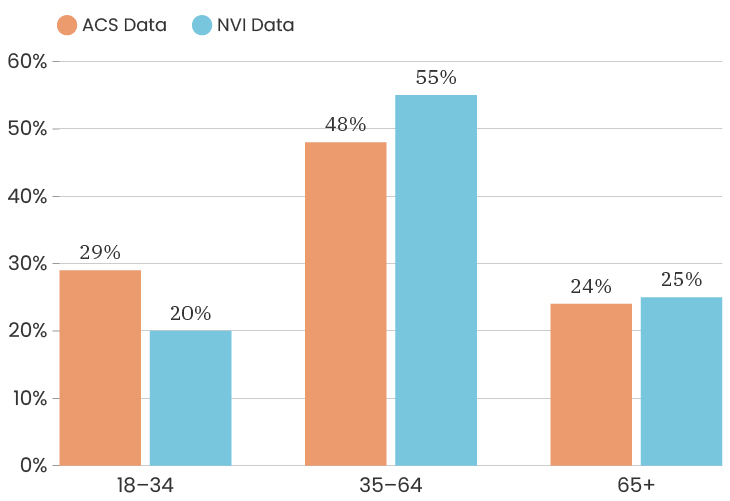
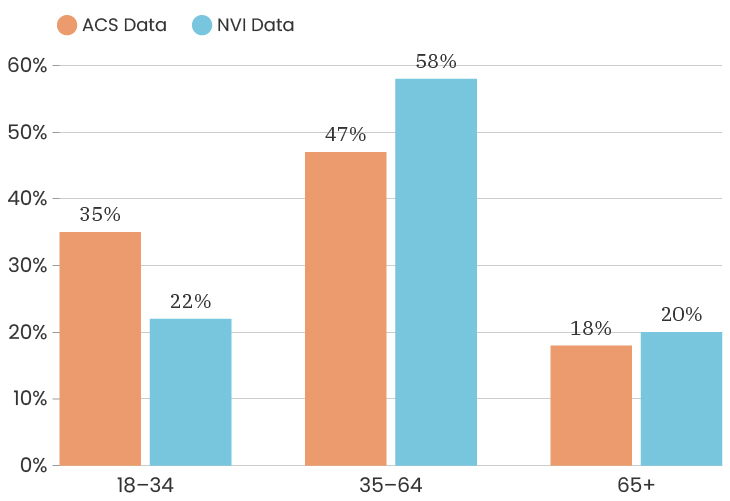
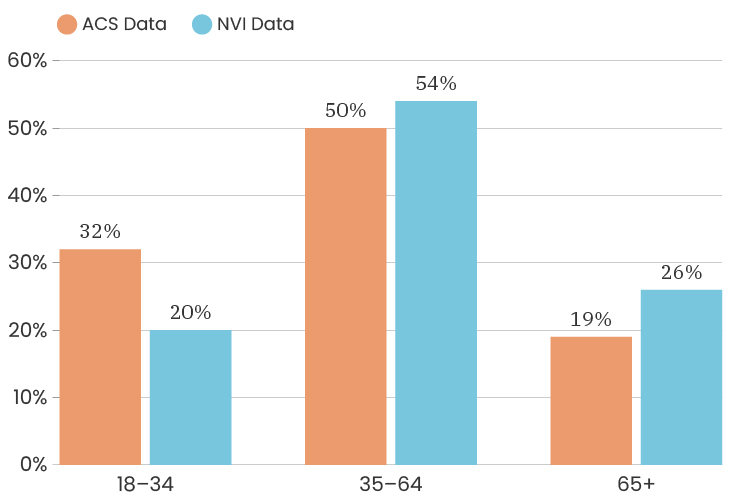
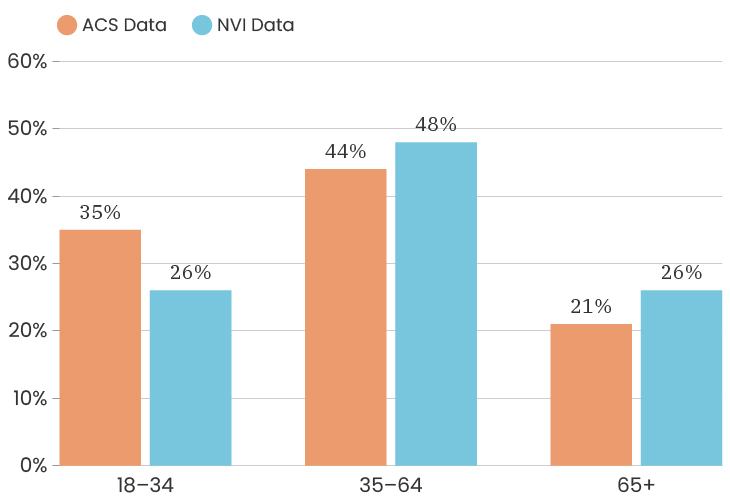
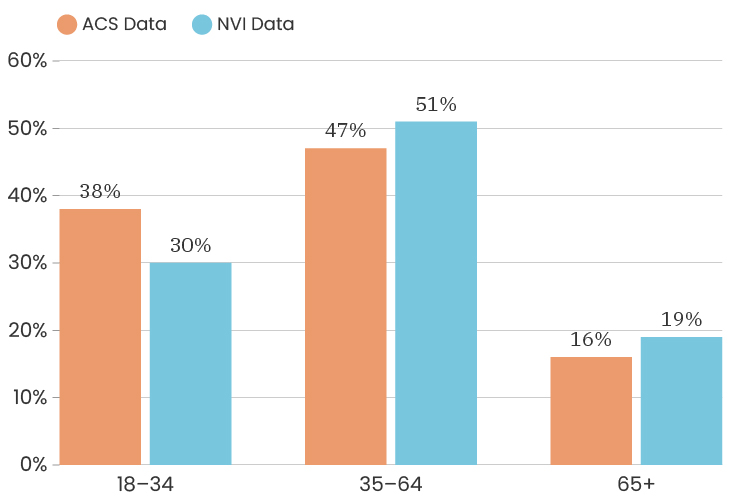
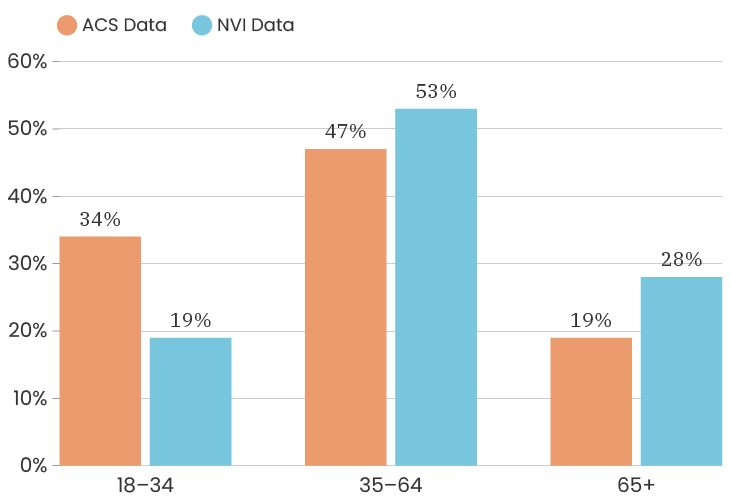
The challenges of collecting data on race and ethnicity in a way that fully reflects how people see themselves are well-documented. Traditionally, the U.S. Census Bureau has collected data on race and ethnicity using separate questions, which has resulted in Hispanic origin being reported separately from race, and Middle Eastern/North African being reported together with White. With NVI, we sought to use an approach that aligns more closely with ongoing federal efforts to gather data in a way that allows residents to select all of the identities with which they identify at once, regardless of whether those are considered racial or ethnic categories. Because of this, it isn’t possible to fully compare race/ethnicity data between the ACS and the NVI, though we have made some efforts to standardize the data as much as possible to give a sense of the areas where the NVI sample most closely resembles Detroit’s overall demographics.
Note also that as the NVI survey used a “select all that apply” approach to identifying race/ethnicity, numbers are likely to add up to more than 100%.
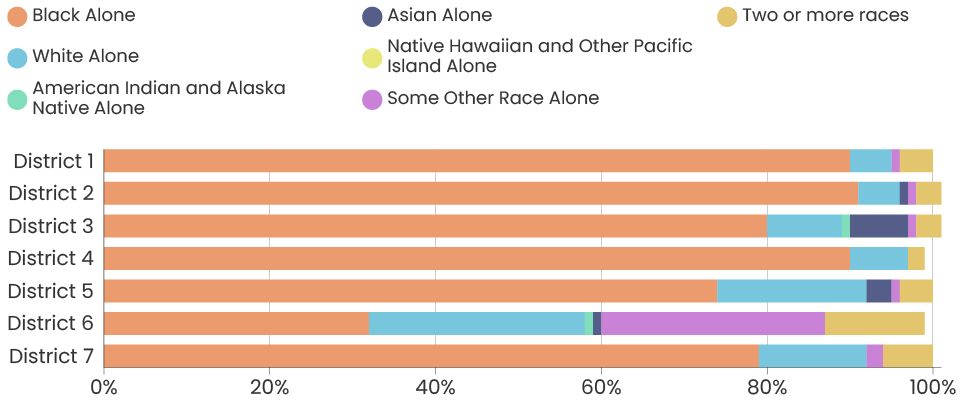
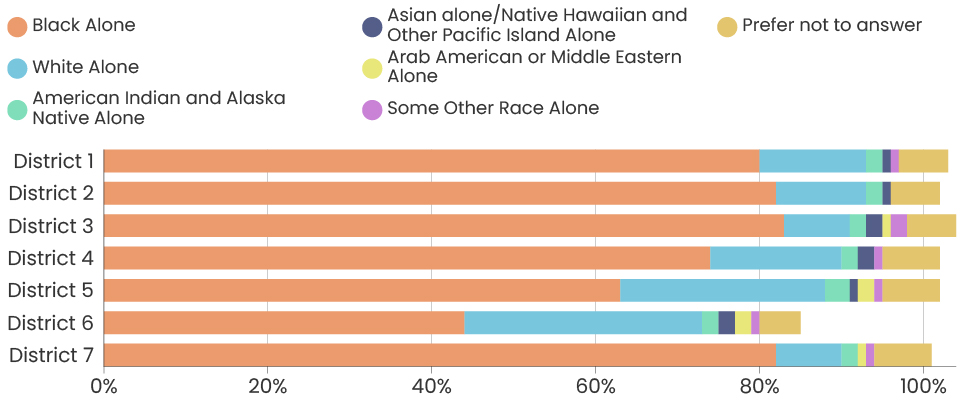
So, back to our initial question, is this data representative? The answer is: it’s complicated. For now, we are saying that yes, the data is representative, but proceed with caution. Over the following months, we are going to do some robustness checks, meaning we are going to take a deep dive into the data to understand how the groups of people who are overrepresented in our sample might impact our data. We will share our results when we finish our analysis.
As we work with our partners to increase the survey responses we get from Detroiters, the more representative this data can be. Reach out if you want to help! And if you want to talk to someone at D3 about how you plan to use the data and what you might want to consider, feel free to ask us by reaching out on our contact page.



